by JumpyTacoGoldman Sachs
Breakthrough in Test-Time Compute
I came across two interesting papers recently on scaling laws in AI and wanted to share a summary. Here are the key takeaways:
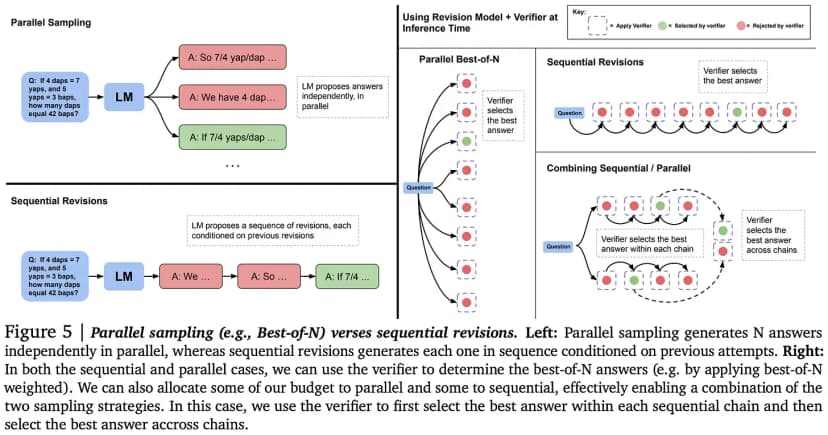
Scaling LLM Test-Time Compute Two papers looked at how to scale up test-time compute for LLMs:
- S...