
How did SarvamAI build Sarvam-1?
Read a superb deep dive The Arc did on How Sarvam AI designed its LLM - thought of summarising the playbook for those interested :)
- Strategic Model Design:
- Focused Scope: Sarvam AI opted for a small, domain-specific LLM (Sarvam-2B) to avoid the AGI (Artificial General Intelligence) route taken by giants like OpenAI and Google. This allows for targeted efficiency, reduced computation, and lower costs.
- Frugal Computing: Emphasis on optimizing tokenization for Indian languages reduces GPU dependency, making it a cost-effective solution for enterprises.
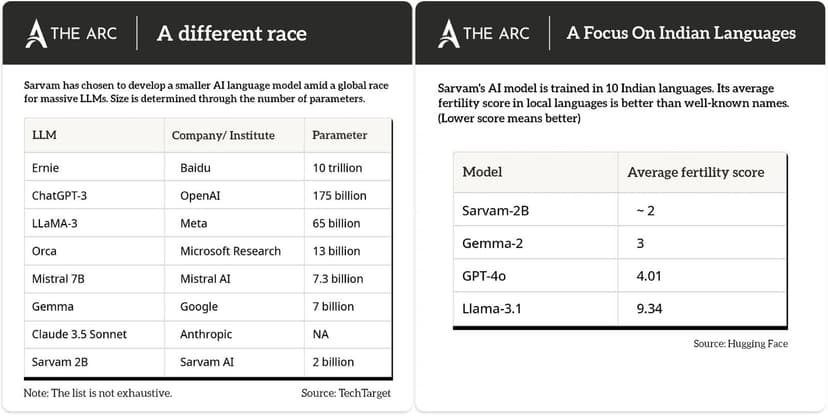
- Indian Language Specialization:
- Tokenization Efficiency: Sarvam’s tokenizer uses 1.4–2.1 tokens per word in Indian languages compared to the typical 4–8 tokens in other LLMs. This enhances cost efficiency and accuracy, essential for scaling in the Indian market.
- Fertility Scores: With an average fertility score of approximately 2, Sarvam outperforms other models like Gemma-2 and GPT-4o in Indian languages, demonstrating superior efficiency in token usage.
- Training Corpus and Data Generation:
- Indic Token Corpus: Sarvam AI trained Sarvam-2B on a massive 4 trillion-token dataset, with specific attention to Indian languages.
- Synthetic Data: Leveraging synthetic data generation methods, Sarvam maximizes the diversity and quality of training data, helping the model learn nuances across 10 Indian languages.
- AI4Bharat Collaboration: Utilizes datasets from AI4Bharat (IIT Madras) to boost local language performance, including crowdsourced data that improves the LLM’s contextual understanding.
- Sector-Specific Applications:
- Banking and Finance: Sarvam powers Setu's Sesame API, enabling fast underwriting by analyzing financial data from the informal sector, making it ideal for India's unique lending ecosystem.
- Voice and Text Interfaces: Sarvam-2B’s proficiency in Indian languages supports Interactive Voice Response (IVR) systems and real-time voice applications, serving industries such as telecom, banking, and customer support.
- Market Fit and Business Model:
- Low-Cost, High-Volume Strategy: Sarvam's efficient design allows for affordable services (for example, Re 1 per minute for voice interactions), making it attractive for enterprises targeting the Indian mass market.
- API-Driven Delivery: Sarvam-2B is available as an API, enabling seamless integration into various applications like personal finance, legal document analysis, and educational tools.
- Tokenization Impact on Cost:
- Token-Based Pricing: The cost of operating LLMs for Indian languages is typically high due to inefficient tokenization. Sarvam counters this with optimized token usage, which minimizes inference costs for Indian languages compared to LLMs like GPT and Llama, making it a practical choice for large-scale enterprise adoption.
- Future Expansion and Adaptability:
- Multilingual Scope: The success of Sarvam in Indian languages paves the way for potential expansion to other underrepresented languages globally.
- Cross-Sector Flexibility: The model's design enables future applications in fields like agriculture, education, and healthcare, where localized language understanding is critical.
Key Takeaway: Sarvam AI has crafted a focused, cost-effective model that excels in Indian languages, offering a scalable, API-driven solution tailored for Indian enterprises. By specializing in high-efficiency tokenization and frugal computing, it presents a sustainable alternative to larger LLMs, setting a new standard for region-specific generative AI applications.
Shoutout to the team at The Arc for this :)
One interview, 1000+ job opportunities
Take a 10-min AI interview to qualify for numerous real jobs auto-matched to your profile 🔑
Quantized models like granite dense are already set to capture this market given their reduced GPU dependency and ability to run on a small GPU. OpenAI api and other cloud solutions aren't very costly either. Sarvam is being overhyped to milk money from investors and is set to fail.